Building Llama 3.2 From Scratch (How Modern LLMs Improved on GPT-2)
Week 2 of the model-atlas series: rebuild a Llama-style decoder block in PyTorch and see why RoPE, RMSNorm, GQA, and SwiGLU became the modern default.
About 6 min read · Technical, beginner-friendly if you know Python
I’m Saran, co-founder of Tekvo. This is week 2 of an open notebook: one model a week, each with runnable code and visuals. Last week I built GPT-2 by hand. This week I rebuilt the small Llama 3.2-style decoder block to answer one question: what actually changed between the classic GPT-2 stack and the LLM architecture most open models use today? The code lives in model-atlas on GitHub.
TL;DR
- Llama 3.2 is still a decoder-only transformer: tokens in, next-token logits out.
- The modern upgrades are mostly engineering choices: RMSNorm, RoPE, GQA, and SwiGLU.
- Compared with GPT-2, Llama-style models are better suited for long context, efficient serving, and local deployment.
- The big lesson: modern LLMs did not replace the transformer block. They made the block cheaper, longer-context, and easier to scale.
Why Llama after GPT-2?
GPT-2 is the cleanest starting point because it shows the original recipe: learned token embeddings, learned position embeddings, multi-head attention, GELU MLP, LayerNorm, and next-token prediction.
Llama is the best next step because it keeps the same mental model while swapping in the parts that became standard in modern open-weight LLMs. If GPT-2 teaches the skeleton, Llama teaches the production shape.
The Llama 3.2 1B model is also small enough to reason about. Meta describes the Llama 3.2 text models as optimized transformer models with grouped-query attention and long-context support in the public model card on Hugging Face and the Llama docs. Sebastian Raschka’s LLM Architecture Gallery is useful here because it makes these architecture differences visible instead of hiding them behind benchmark numbers.
The architecture
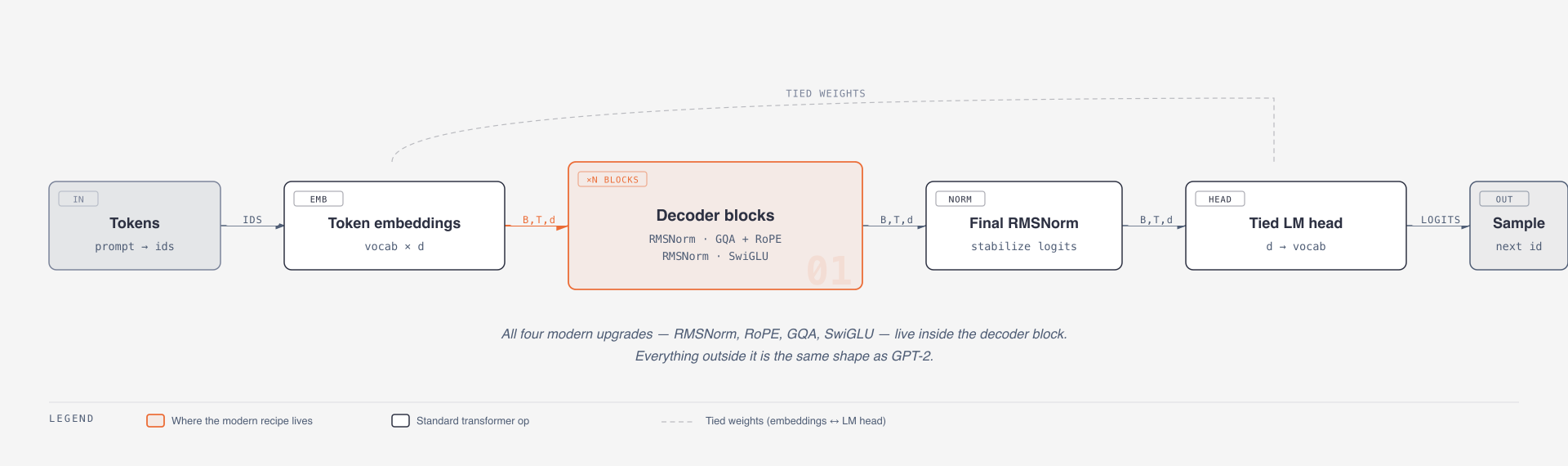
At a high level, Llama 3.2 is still:
tokens -> embeddings -> repeated decoder blocks -> final norm -> LM headThe interesting changes are inside the decoder block.
Input hidden state
-> RMSNorm
-> Grouped-Query Self-Attention with RoPE
-> Residual add
-> RMSNorm
-> SwiGLU feed-forward network
-> Residual add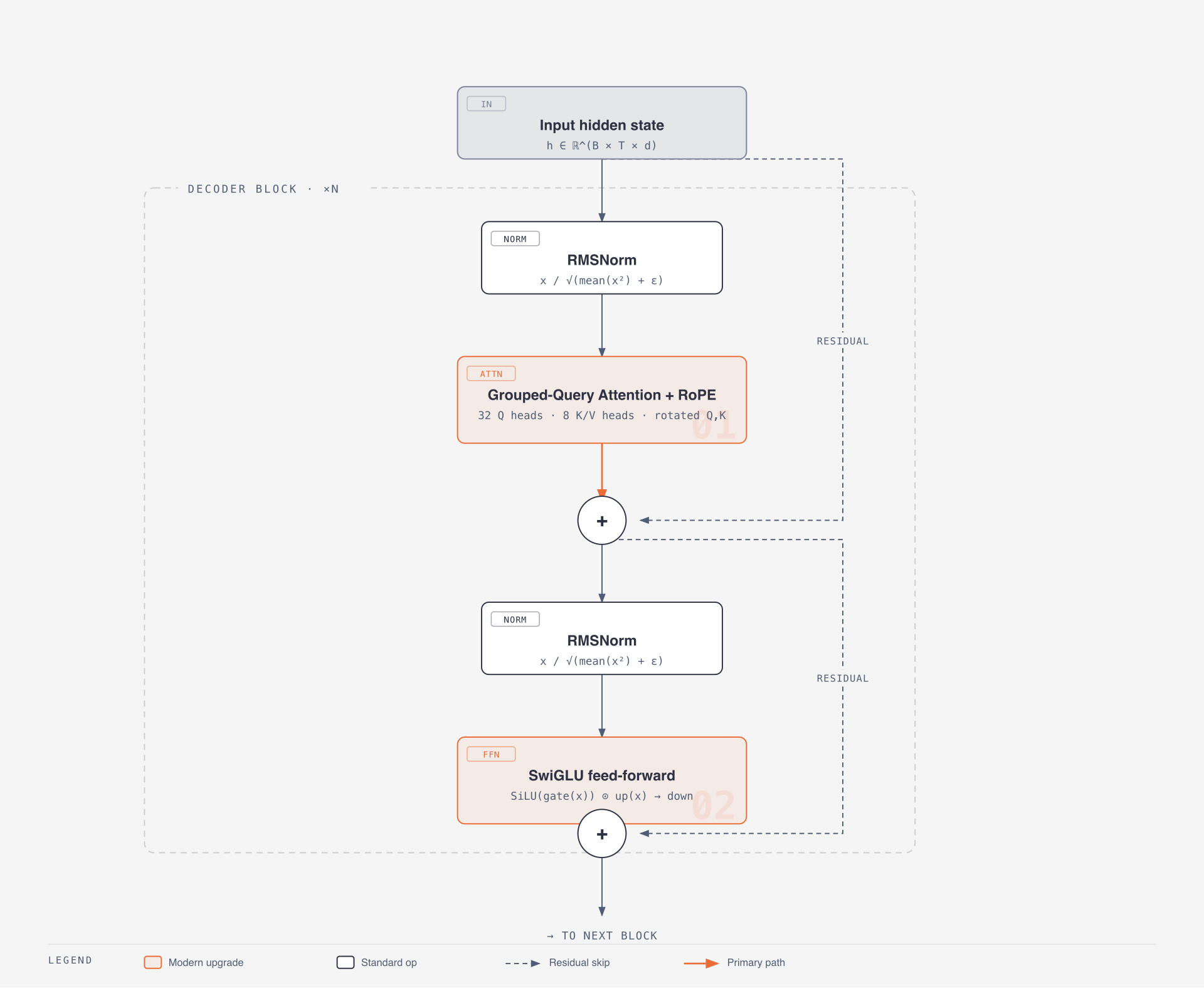
What changed from GPT-2?
| Component | GPT-2 | Llama 3.2-style stack | Why it matters |
|---|---|---|---|
| Position | Learned absolute position embeddings | RoPE | Better relative position behavior and long-context scaling |
| Attention | Multi-head attention | Grouped-query attention | Lower KV-cache memory during inference |
| Normalization | LayerNorm | RMSNorm | Simpler normalization, no mean subtraction |
| FFN | GELU MLP | SwiGLU MLP | Stronger gated feed-forward block |
| Context | 1,024 tokens in GPT-2 small | Much longer context in Llama 3.2 text models | More useful for documents, agents, and code |
| Tokenizer | GPT-2 BPE vocabulary | Larger modern tokenizer | Better coverage across code and multilingual text |
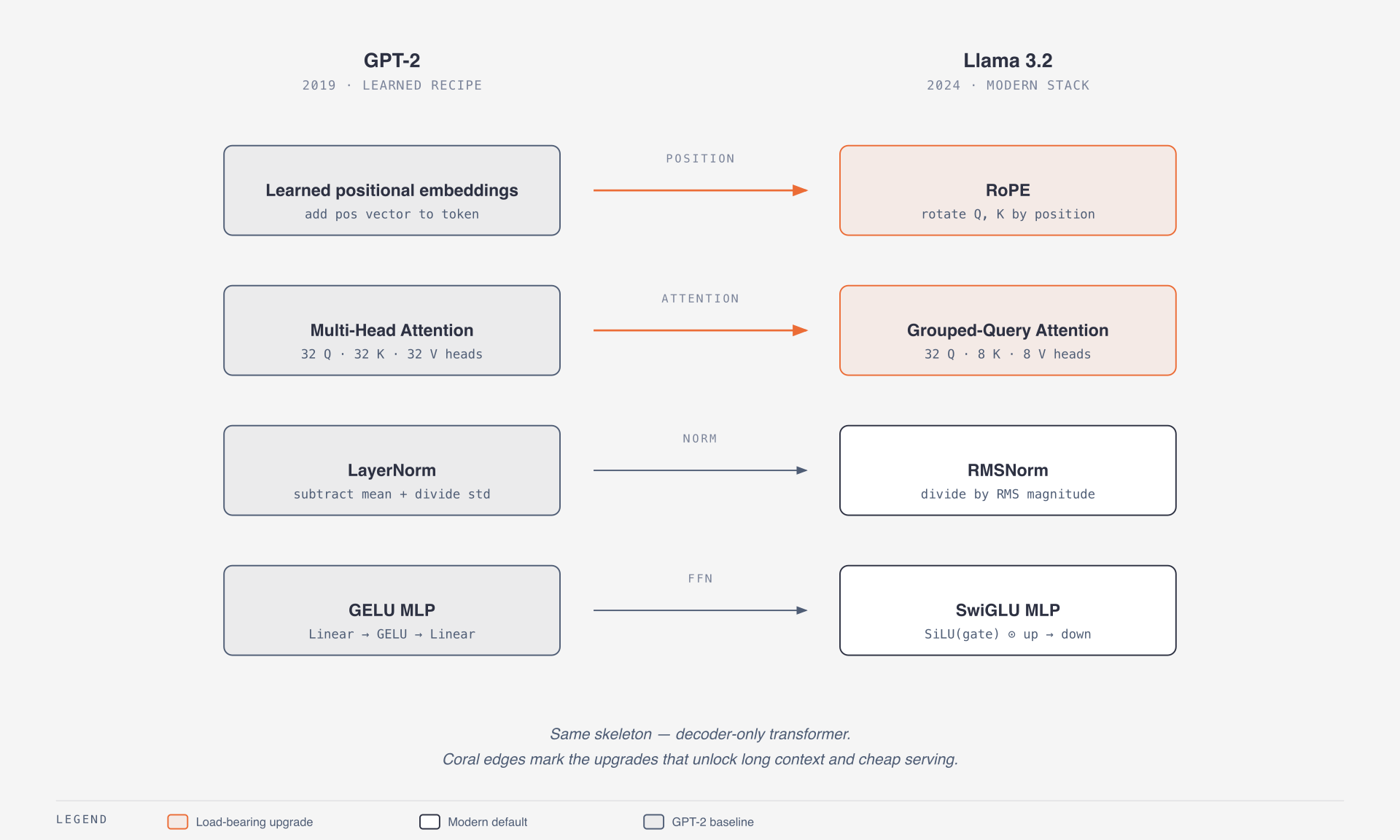
None of these changes alter the core training objective. The model still predicts the next token. But each change removes a bottleneck that shows up when you scale model size, context length, or serving traffic.
The four modern upgrades
1. RMSNorm
GPT-2 uses LayerNorm:
y = (x - mean(x)) / sqrt(var(x) + eps)Llama uses RMSNorm:
y = x / sqrt(mean(x * x) + eps)RMSNorm skips mean subtraction. That sounds small, but at LLM scale “small” operations happen billions of times. The idea is simple: normalize the magnitude of the vector, then learn a scale.

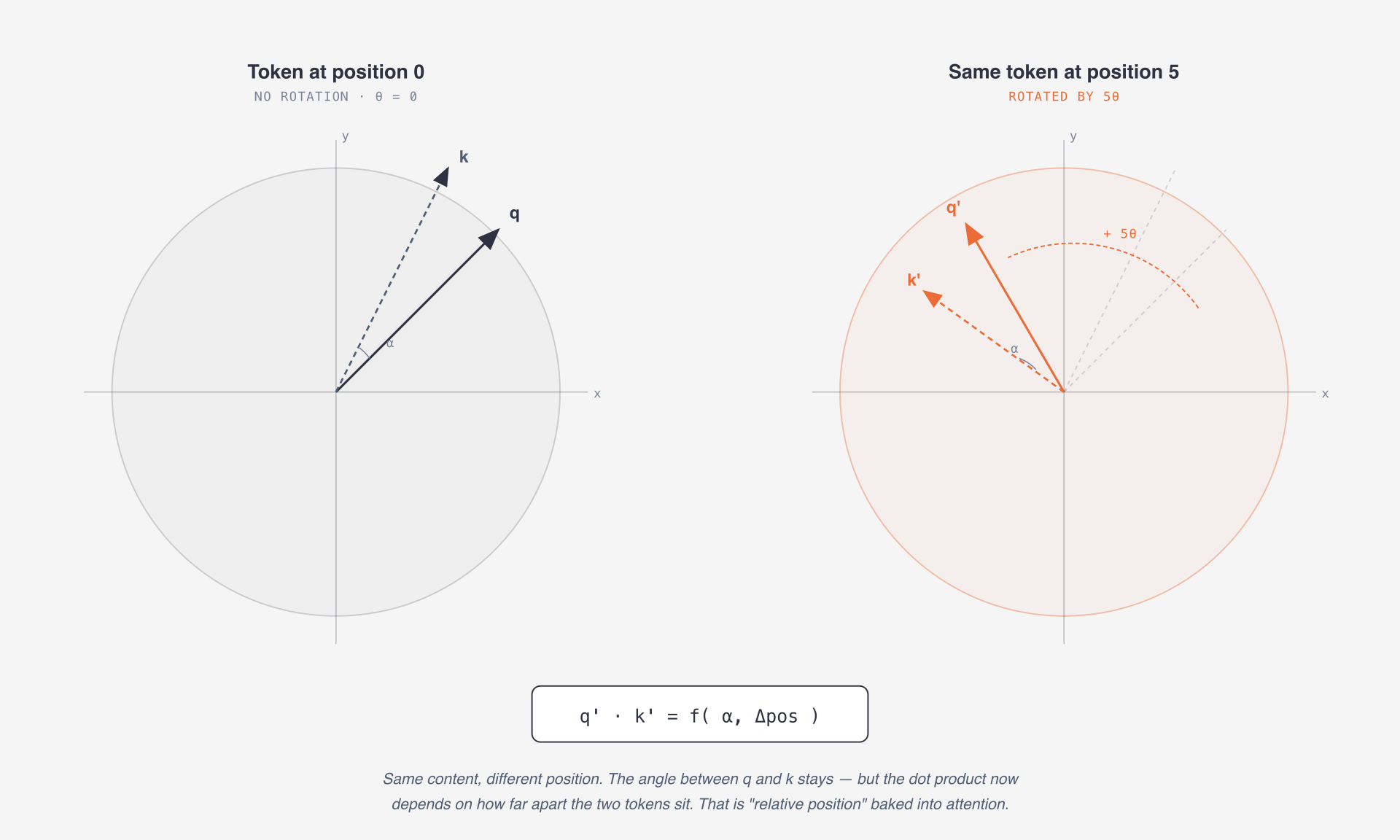
2. RoPE
GPT-2 learns a position embedding table. Position 0 has a vector. Position 1 has a vector. The model adds those vectors to token embeddings.
RoPE does something different: it rotates query and key vectors based on position before computing attention. This lets attention scores carry relative position information directly.
The useful intuition:
GPT-2: "add a learned position vector to the token"
RoPE: "rotate attention vectors so distance is built into Q dot K"That is one reason Llama-style models are a better foundation for long-context systems.
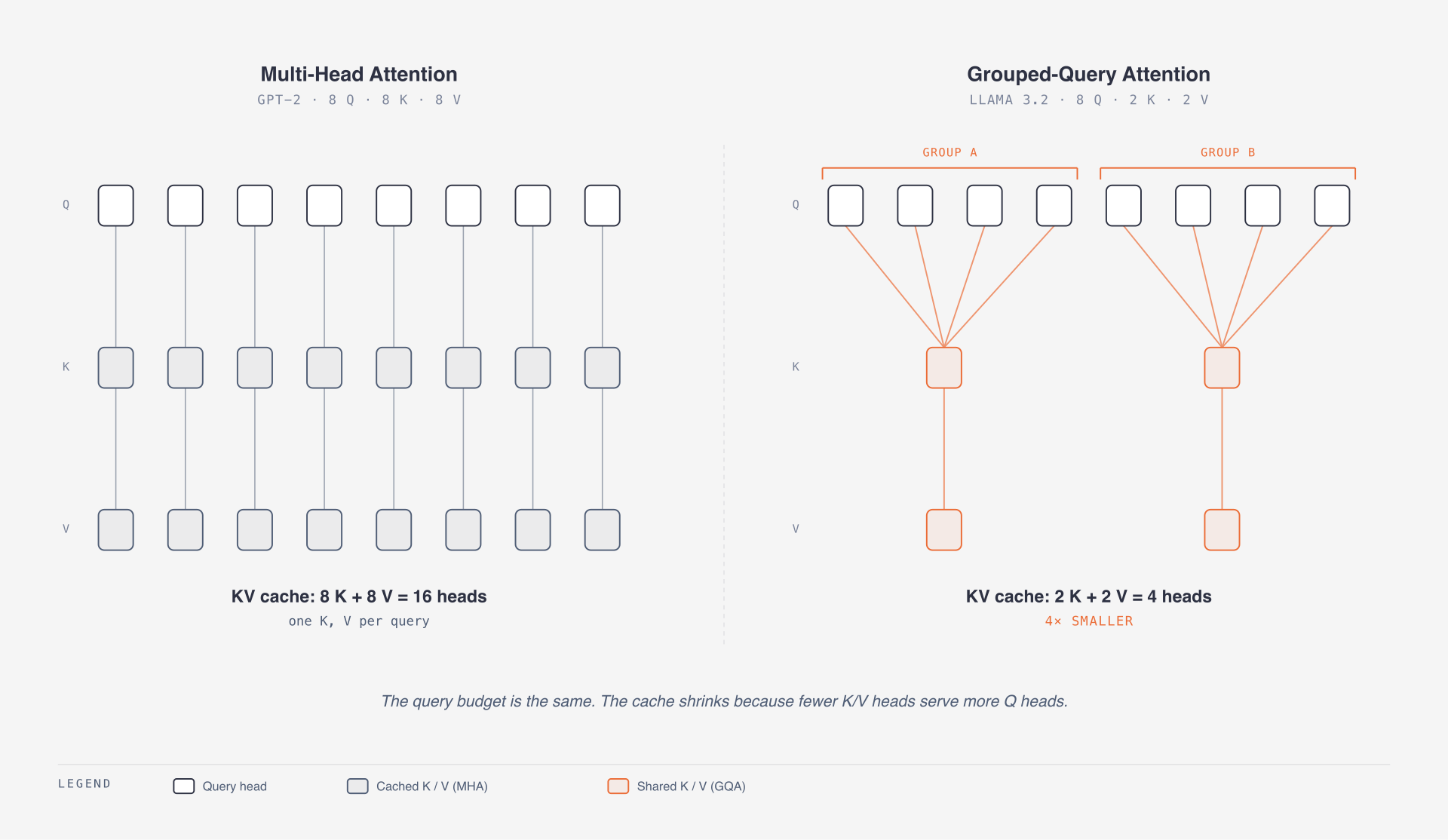
3. Grouped-query attention
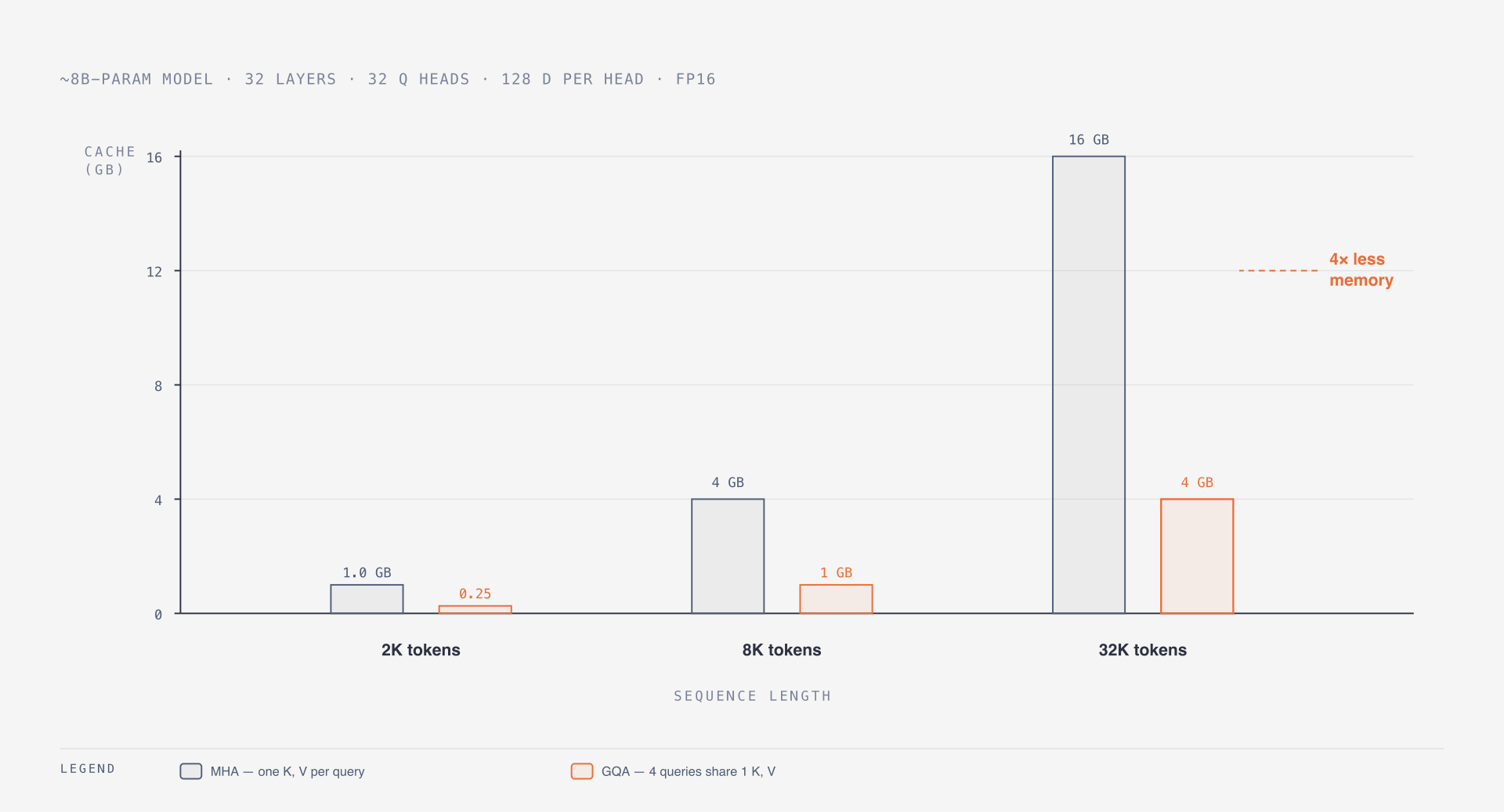
In classic multi-head attention, every query head has its own key and value head. During generation, the server stores all previous keys and values in the KV cache. Long context makes this expensive.
Grouped-query attention keeps many query heads but shares fewer key/value heads across them.
MHA: 32 query heads, 32 key heads, 32 value heads
GQA: 32 query heads, 8 key heads, 8 value headsThe output still has many query heads, but the cache is smaller. That matters in production because KV-cache memory is often the reason long-context inference gets slow or expensive.
4. SwiGLU
GPT-2 uses a simple GELU feed-forward network:
x -> Linear -> GELU -> LinearLlama uses a gated feed-forward block:
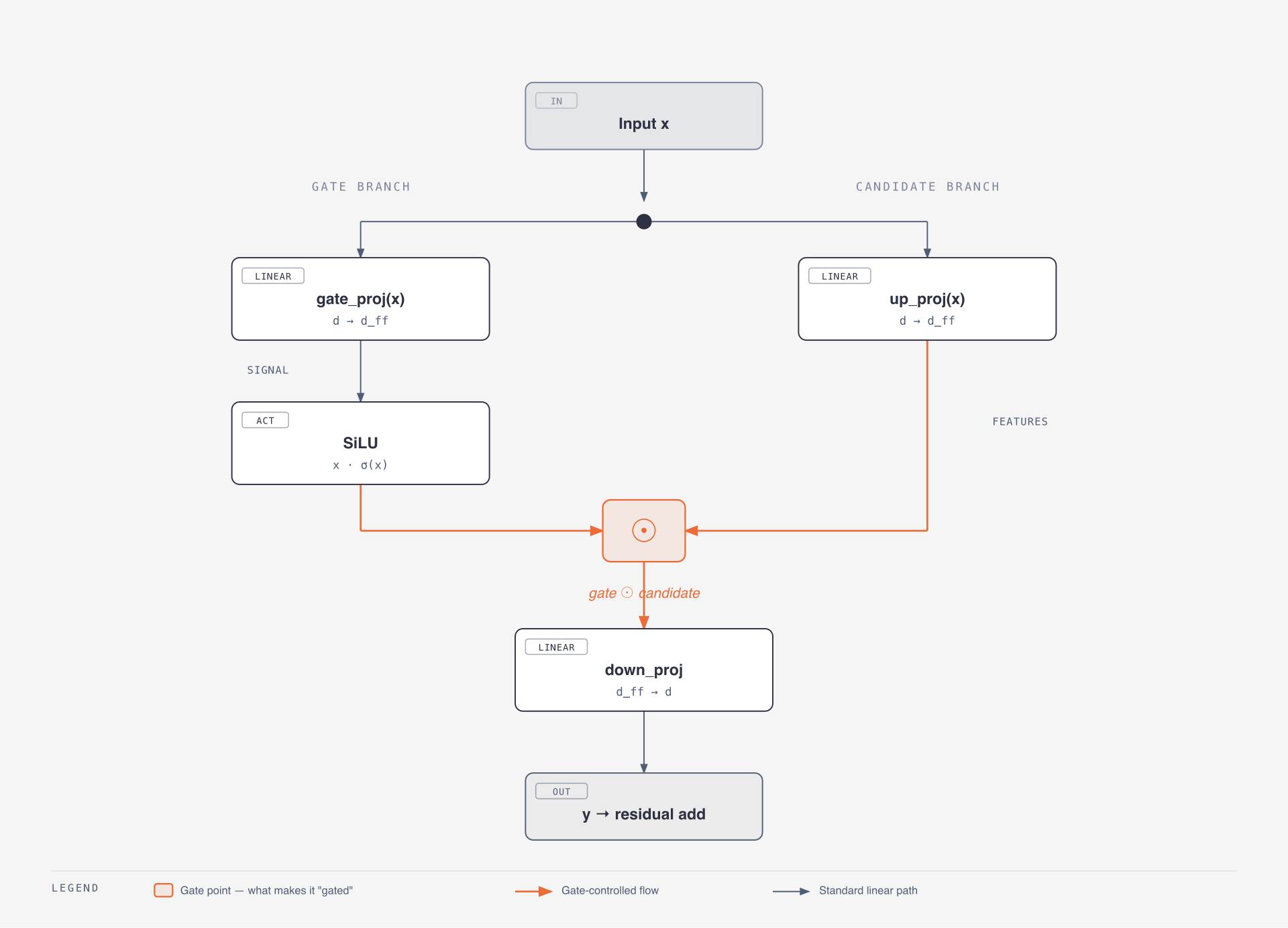
x -> SiLU(gate_proj(x)) * up_proj(x) -> down_projOne branch decides what to let through; the other branch carries candidate features. The multiplication makes the feed-forward layer more expressive without changing the basic transformer loop.
What I built
The code for this week implements the core Llama-style decoder in PyTorch:
- token embeddings
- RMSNorm
- RoPE
- grouped-query self-attention
- SwiGLU feed-forward network
- tied LM head
- small config that runs on a laptop
Run it locally:
git clone https://github.com/saran-io/model-atlas.git
cd model-atlas/models/02-llama32-from-scratch/code
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
python llama32.py --prompt "The future of open models is" --max_new_tokens 40The default config is intentionally tiny. It is not trying to reproduce Meta’s weights. It is a readable implementation of the architecture pattern, so the math lines up with the diagrams.
Where this applies
Llama-style models are useful when you care about:
- Local AI features — small open-weight models can run on laptops, edge devices, or private servers.
- Private enterprise workflows — teams can host models closer to sensitive data.
- Agent backends — long context plus efficient KV cache helps tool-using systems carry more state.
- RAG pipelines — open models can be tuned, quantized, routed, and evaluated inside your own stack.
- Model learning — Llama is the architecture family you need to understand before reading most modern open LLM repos.
Production lesson
At Tekvo AI, most model decisions are not “which benchmark is highest?” They are tradeoffs:
- How much context does the task really need?
- What is the latency budget?
- Can we send this data to a hosted API?
- Does the model need tool use, coding ability, or multilingual coverage?
- Can a small local model handle 80% of the traffic?
Llama matters because it gives builders a model family they can inspect, deploy, quantize, and adapt. You do not get that with a closed API.
Remember
- GPT-2 and Llama are the same species: decoder-only transformers trained for next-token prediction.
- RMSNorm simplifies normalization.
- RoPE moves position information into attention instead of adding a learned position vector.
- GQA reduces KV-cache pressure, which matters for long-context inference.
- SwiGLU makes the feed-forward block stronger through gating.
Verdict
GPT-2 is the best model to learn the transformer. Llama is the best next model to learn what modern LLM engineering looks like.
If Week 1 answered “how does a language model work?”, Week 2 answers “what did modern open models change to make this practical at scale?”
Week 2/24. Next up: Mixture-of-Experts with Mistral/Mixtral, where the model gets bigger without activating every parameter on every token.