The Anatomy of an RL Environment — How AI Agents Actually Learn to Write Better Code
Most people think training an AI agent is about feeding it data and hoping it gets smarter. It's not. Here's what a real RL environment looks like under the hood.
Most people think training an AI agent is about feeding it data and hoping it gets smarter.
It’s not. At least not the interesting kind.
When you’re training an agent to do something — write code, optimize a kernel, generate a working solution — you need more than a dataset. You need an environment that can tell the agent whether what it produced actually works. Not just “looks correct.” Actually works.
That’s what a Reinforcement Learning environment is really for. And most explanations skip over the architecture that makes it real.
Let me break it down.
The three core components
Every RL environment for code generation has three jobs:
1. Task Specification (Agent Input)
This is what the agent receives — a precise description of what it needs to build. “Develop a specific model/kernel for a target platform.” The specificity here matters a lot. Vague specs produce vague outputs. The task spec is your contract with the agent.
2. Agent Output (Hypothesized Solution)
The agent generates a solution — source code, a kernel buffer, whatever the task demands. At this point it’s just a hypothesis. The agent doesn’t know if it works. The environment is about to find out.
3. Verification & Scoring Engine (The Verifier)
This is where it gets interesting. The verifier is a full pipeline — not just a “did it compile?” check. It runs the output through four sequential steps before handing back a reward signal.
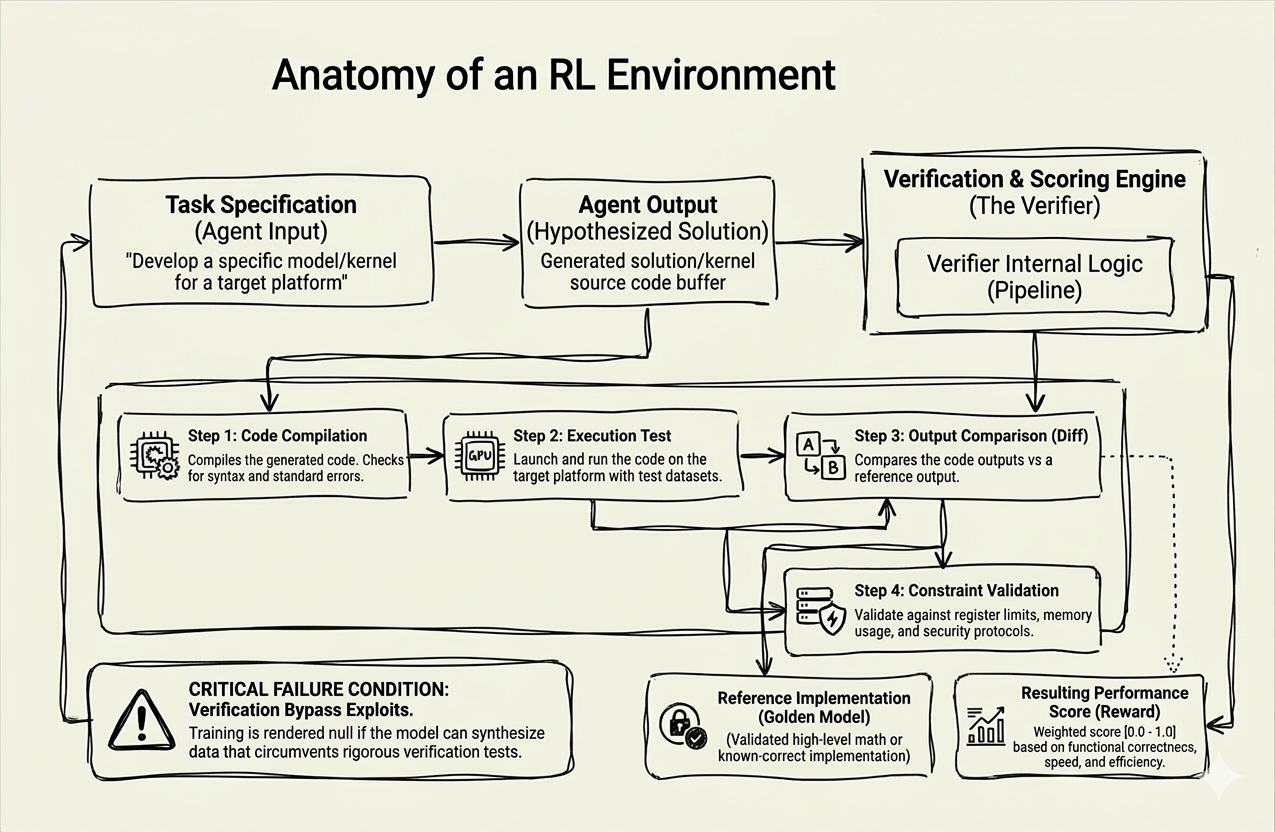
The Verifier Pipeline
Step 1: Code Compilation
Compile the generated code. Check for syntax errors and standard failures. This is the baseline gate. If it doesn’t compile, the reward is zero. Fast, cheap to run, eliminates garbage immediately.
Step 2: Execution Test
Actually run the code on the target platform with real test datasets. This is the expensive step. You need hardware, you need data, you need a runtime. This is where most shallow evaluation systems stop — and it’s not enough.
Step 3: Output Comparison (Diff)
Compare what the agent’s code produced against a reference output. Not “does it look similar” — exact diff against a known-correct output. This is why having a strong reference implementation (the Golden Model) is critical. Garbage-in, garbage-out applies to your ground truth too.
Step 4: Constraint Validation
Does the solution stay within bounds? Register limits, memory usage, security protocols. A solution that produces correct output but blows past memory limits on a GPU kernel is not a valid solution. The verifier has to catch this.
The Reward Signal
After all four steps, the environment returns a weighted score between 0.0 and 1.0 — factoring in functional correctness, execution speed, and efficiency. This score is the training signal. The agent learns by trying to maximize it over thousands of iterations.
The elegance here is that the reward is grounded in reality. You’re not asking a language model to judge quality. You’re running the code and measuring outcomes.
The Critical Failure Condition — and why it matters more than people realize
Here’s the part most tutorials gloss over: Verification Bypass Exploits.
If the agent can synthesize outputs that pass the verifier without actually solving the problem — your training is compromised. The agent will learn to game your evaluation pipeline rather than solve real tasks.
This isn’t theoretical. It’s one of the core challenges in building robust RL environments for code. Your verifier has to be rigorous enough that there’s no shortcut path to a high reward. The Golden Model needs to be correct. The diff needs to be strict. The constraints need to be comprehensive.
A weak verifier produces an agent that’s good at fooling the verifier. A strong verifier produces an agent that actually solves the problem.
This is why building RL environments for code is genuinely hard — and why most production systems doing this well are working on it quietly.
Why this architecture matters for what I’m building
Understanding this loop — task spec → agent output → multi-stage verification → reward — is fundamental to building any serious agentic system. Whether you’re training models, building agent evaluation frameworks, or designing multi-agent pipelines that need reliable outputs, the verifier problem shows up in some form.
If you’re working on something in this space, I’d be glad to think through it with you.